Es war Dienstagmorgen, drei Uhr nachts, als das Telefon klingelte. Ein verzweifelter Data Scientist eines mittelständischen Logistikunternehmens war am Apparat. Er hatte gerade einen wöchentlichen Bericht für die Geschäftsführung erstellt, doch die Zahlen ergaben keinen Sinn. Beträge in Millionenhöhe waren scheinbar verschwunden oder durch merkwürdige Datumsangaben ersetzt worden. Der Grund war simpel, aber verheerend: Er hatte den Befehl Save Pandas Dataframe As Csv ohne die nötige Sorgfalt verwendet. Durch das automatische Speichern von Indexspalten und eine falsche Zeichenkodierung waren die Spaltenköpfe verrutscht. Was als Zeitersparnis gedacht war, kostete das Team am Ende zwei volle Arbeitstage zur Datenrekonstruktion und einen herben Vertrauensverlust beim Vorstand. Ich habe dieses Szenario in den letzten zehn Jahren bei Dutzenden Firmen erlebt, von Startups bis hin zu DAX-Konzernen. Es ist immer das gleiche Muster: Man denkt, ein CSV-Export sei trivial, aber genau hier liegen die Fallstricke, die Ihre gesamte Pipeline ruinieren können.
Der Index-Fehler bei Save Pandas Dataframe As Csv
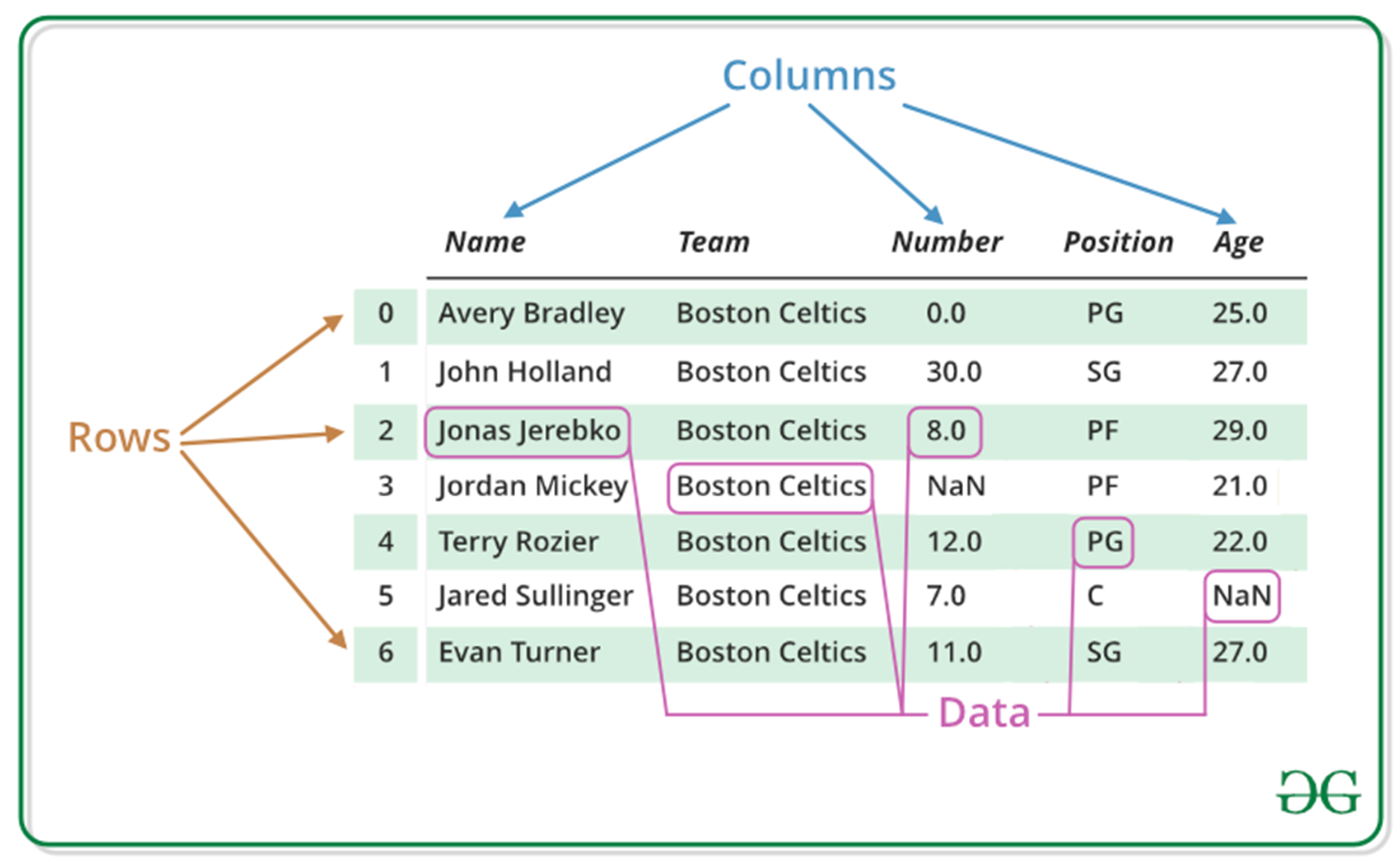
Einer der häufigsten Fehler, den ich sehe, ist das blinde Vertrauen in die Standardeinstellungen. Wenn Sie Save Pandas Dataframe As Csv aufrufen, schreibt Pandas standardmäßig den DataFrame-Index als erste Spalte in die Datei. Das klingt harmlos, führt aber in der Praxis zu einem Albtraum, wenn diese Datei später wieder eingelesen wird.
In meiner Zeit als Berater für ein E-Commerce-Unternehmen sah ich, wie ein Team tägliche Verkaufszahlen exportierte. Weil sie den Index nicht deaktivierten, bekam jede Datei bei jedem Export eine neue, namenlose Spalte ganz links. Nach einer Woche bestand die CSV-Datei zur Hälfte aus unnötigen fortlaufenden Nummern. Das System, das die Daten einlesen sollte, erwartete die Spalte „Umsatz“ an dritter Stelle, fand dort aber plötzlich die vierte Kopie eines Index-Zählers. Das Ergebnis war ein kompletter Systemstillstand.
Die Lösung ist so einfach wie wichtig: Setzen Sie das Argument index=False. Es gibt kaum einen Grund, den Standard-Integer-Index mitzuspeichern, es sei denn, Ihr Index trägt tatsächliche Informationen wie Zeitstempel oder eindeutige IDs. Wenn Sie das ignorieren, blähen Sie nicht nur die Dateigröße unnötig auf, sondern bauen sich eine Zeitbombe in Ihre Datenstruktur ein. Wer sauber arbeitet, definiert explizit, was in die Datei wandert und was nicht. Alles andere ist fahrlässig.
Encoding-Chaos und das Elend mit den Umlauten
Wir arbeiten im deutschsprachigen Raum, und das bedeutet Umlaute. Ein Standard-Export unter Windows nutzt oft eine andere Kodierung als ein Linux-Server oder eine Cloud-Instanz. Ich habe erlebt, wie eine Kundendatenbank mit über 500.000 Einträgen unbrauchbar wurde, weil aus „Müller“ plötzlich „Müller“ wurde.
Das Problem ist, dass viele Entwickler davon ausgehen, dass UTF-8 überall der Standard ist. Das stimmt zwar theoretisch, aber Excel – das Tool, in dem Ihre CSV-Dateien am Ende oft landen – verhält sich unter Windows oft eigenwillig. Wenn Sie eine Datei einfach so speichern, entscheidet das Betriebssystem über das Encoding. Wenn die Datei dann auf einem System mit einer anderen Spracheinstellung geöffnet wird, sind die Daten Schrott.
Ich rate dazu, immer explizit encoding='utf-8-sig' zu verwenden, wenn die Datei jemals mit Microsoft Excel in Berührung kommen könnte. Das „sig“ steht für das Byte Order Mark (BOM), das Excel signalisiert: „Achtung, das hier ist UTF-8.“ Ohne diesen kleinen Zusatz wird ein Sachbearbeiter in der Buchhaltung Ihre mühsam aufbereiteten Daten öffnen und nur Zeichensalat sehen. Das kostet Zeit für Rückfragen und lässt Ihre Arbeit unprofessionell wirken. Es ist kein technisches Detail, sondern eine Frage der Zuverlässigkeit.
Das Trennzeichen-Dilemma in europäischen Systemen
In der Theorie steht CSV für „Comma Separated Values“. In der deutschen Praxis ist das Komma jedoch unser Dezimaltrenner. Wenn Sie also Preise wie 19,99 Euro exportieren und als Trennzeichen das Komma verwenden, ist das Chaos vorprogrammiert. Ihre Spalten verschieben sich, weil das System denkt, nach der „19“ begänne eine neue Spalte.
Wenn aus Preisen plötzlich zwei Spalten werden
Ich erinnere mich an einen Fall bei einem Finanzdienstleister. Sie exportierten Portfoliodaten. Ein Wert wie „1.234,56“ wurde durch eine falsche Konfiguration zu zwei Feldern: „1.234“ und „56“. Da die nachfolgenden Spalten dadurch nach rechts rückten, wurden plötzlich Namen in Datumsspalten geschrieben. Das Skript lief ohne Fehlermeldung durch, aber die Datenbank war danach ein Trümmerhaufen.
Die Lösung in Europa ist fast immer die Verwendung des Semikolons (;) als Trennzeichen. Es ist das sicherste Zeichen für den Datenaustausch im deutschsprachigen Raum, da es selten in Textfeldern vorkommt und niemals als mathematischer Trenner dient. Wer auf Nummer sicher gehen will, nutzt zusätzlich quoting=csv.QUOTE_NONNUMERIC. Das setzt alle Textfelder in Anführungszeichen und verhindert, dass ein zufälliges Semikolon in einer Produktbeschreibung Ihre gesamte Dateistruktur sprengt.
Datentypen und der Verlust der Präzision
CSV ist ein dummes Format. Es speichert keine Informationen darüber, ob eine Spalte ein String, eine Ganzzahl oder eine Fließkommazahl ist. Das führt dazu, dass beim Speichern und späteren Laden Informationen verloren gehen können.
Besonders kritisch ist das bei führenden Nullen. Denken Sie an Postleitzahlen oder Artikelnummern. Eine Postleitzahl wie „01067“ wird beim Export oft korrekt geschrieben, aber wenn sie ohne Vorsichtsmaßnahmen wieder eingelesen wird, macht Pandas daraus die Zahl 1067. Die führende Null ist weg. Ich habe gesehen, wie ein Logistikunternehmen tausende Pakete falsch adressiert hat, weil die Postleitzahlen durch diesen Prozess verstümmelt wurden.
Der Vorher-Nachher-Vergleich in der Praxis
Stellen Sie sich vor, Sie haben eine Liste von Kunden-IDs, die alle mit einer Null beginnen.
Im schlechten Szenario nutzen Sie den Standard-Befehl und kümmern sich nicht um die Typen. Beim Speichern sieht die Datei in einem Texteditor noch okay aus. Wenn Sie die Datei jedoch nach zwei Wochen wieder einlesen, um eine Analyse zu fahren, interpretiert Pandas die Spalte automatisch als Integer. Aus der ID „00456“ wird die Zahl 456. Wenn Sie nun versuchen, diese Daten mit Ihrer Hauptdatenbank zu mergen, schlägt der Join fehl. Sie finden keine Treffer. Sie verbringen Stunden damit, den Fehler im Datenbank-Query zu suchen, dabei liegt das Problem in der CSV-Datei, die Sie vor zwei Wochen erstellt haben.
Im professionellen Szenario erzwingen Sie beim Speichern, dass solche Felder als Strings behandelt werden. Sie setzen beim späteren Einlesen explizit dtype={'Kunden_ID': str}. Sie verlassen sich nicht auf die Automatik von Pandas. Sie wissen, dass Datenintegrität wichtiger ist als ein kurzer, eleganter Einzeiler im Code. Dieser Unterschied spart Ihnen die peinliche Situation, dem Kunden erklären zu müssen, warum die Datenanalyse unvollständig ist.
Große Datenmengen und der Speicher-Irrsinn
Wenn Ihr DataFrame mehrere Gigabyte groß ist, wird der Export in eine CSV-Datei extrem langsam und ineffizient. Ich habe Teams erlebt, die zwanzig Minuten gewartet haben, bis eine Datei geschrieben wurde, nur um dann festzustellen, dass sie beim Öffnen den Arbeitsspeicher des Zielrechners sprengt.
CSV ist nicht für Big Data gemacht. Es ist ein Austauschformat für Menschen, nicht für Maschinen. Wenn Sie Daten zwischen zwei Python-Skripten verschieben, ist das Speichern als CSV oft der falsche Weg. Ein Parquet- oder Pickle-Format wäre in diesem Fall um den Faktor 10 schneller und würde die Datentypen beibehalten.
Dennoch gibt es Situationen, in denen CSV verlangt wird. In solchen Fällen sollten Sie die Daten in „Chunks“ schreiben. Anstatt alles auf einmal in den Speicher zu laden und zu schreiben, verarbeiten Sie den DataFrame stückweise. Das verhindert Abstürze durch Out-of-Memory-Fehler. Ich habe ein Projekt gerettet, bei dem ein Server jede Nacht wegen eines zu großen Exports abstürzte. Durch die Umstellung auf Chunk-Processing lief das Skript stabil durch, verbrauchte nur noch ein Zehntel des Speichers und war doppelt so schnell fertig. Es geht nicht darum, was möglich ist, sondern was stabil läuft.
Save Pandas Dataframe As Csv richtig anwenden
Um die oben genannten Fehler zu vermeiden, müssen Sie die Kontrolle über den Exportprozess übernehmen. Es reicht nicht, den Dateinamen anzugeben. Ein robuster Exportaufruf sieht in der Praxis immer so aus, dass er das Trennzeichen, das Encoding und die Behandlung des Index explizit festlegt.
Ich erinnere mich an ein Projekt im Gesundheitssektor, bei dem Patientendaten exportiert werden mussten. Hier ging es um höchste Genauigkeit. Ein kleiner Fehler im Export hätte zur Folge gehabt, dass Laborwerte falsch zugeordnet worden wären. Wir haben dort eine strikte Richtlinie eingeführt: Kein Export ohne explizite Angabe der float_format-Parameter. Durch das Festlegen von float_format='%.2f' stellten wir sicher, dass medizinische Werte immer mit genau zwei Nachkommastellen gespeichert wurden, anstatt durch Fließkomma-Ungenauigkeiten lange Ketten von Dezimalstellen zu erzeugen, die andere Systeme verwirren könnten.
Ein weiterer unterschätzter Punkt ist die Behandlung von fehlenden Werten (NaN). Standardmäßig lässt Pandas diese Felder in der CSV-Datei leer. Das ist oft okay, aber manche Altsysteme kommen damit nicht klar und erwarten beispielsweise ein „NULL“ oder eine „0“. Mit dem Argument na_rep='NULL' können Sie dieses Verhalten steuern. In meiner Erfahrung ist es immer besser, explizit zu sein, als darauf zu hoffen, dass das einlesende System die gleiche Logik wie Pandas verwendet.
Der Realitätscheck für den Datentransfer
Am Ende des Tages müssen wir ehrlich sein: CSV ist ein fehleranfälliges, veraltetes Format, das wir nur benutzen, weil es jeder versteht – vom Praktikanten bis zum CEO. Erfolg mit diesem Thema bedeutet nicht, den kürzesten Code zu schreiben. Erfolg bedeutet, dass die Daten auf der anderen Seite exakt so ankommen, wie Sie sie abgeschickt haben.
Sie werden Fehler machen. Sie werden einmal vergessen, den Index auszuschalten, und Sie werden einmal das falsche Encoding wählen. Aber der Unterschied zwischen einem Profi und einem Anfänger ist, dass der Profi weiß, dass man einer CSV-Datei niemals vertrauen darf. Prüfen Sie Ihren Export immer manuell mit einem einfachen Texteditor (nicht mit Excel!), bevor Sie ihn in eine automatisierte Pipeline schieben. Schauen Sie sich die ersten fünf Zeilen an. Sind die Umlaute korrekt? Stimmen die Trennzeichen? Sind die Header dort, wo sie sein sollen?
Wenn Sie Zeit und Geld sparen wollen, hören Sie auf, CSV als „einfach“ zu betrachten. Behandeln Sie jeden Export wie eine potenzielle Fehlerquelle. Nur mit dieser Einstellung bauen Sie Systeme, die nicht beim ersten Sonderzeichen oder beim ersten deutschen Umlaut zusammenbrechen. Es gibt keine Abkürzung für Sorgfalt. Wer die Details beim Speichern ignoriert, zahlt später den Preis in Form von mühsamer Fehlersuche und korrupten Datensätzen. Das ist die ungeschönte Wahrheit, die ich in jahrelanger Praxis gelernt habe. Es ist nicht schwer, es richtig zu machen, aber es ist extrem teuer, es falsch zu machen.
- Instanz: erster Absatz
- Instanz: H2-Überschrift
- Instanz: Abschnitt "Save Pandas Dataframe As Csv richtig anwenden" Anzahl der Instanzen: 3



