Stell dir vor, du baust ein riesiges Lagerhaus für ein deutsches Logistikunternehmen wie DHL oder Kühne + Nagel. Jedes Paket braucht einen festen Platz, eine eindeutige Nummer und eine Verbindung zu einem Absender. Wenn du hier schlampst, verlierst du den Überblick und dein System bricht unter der Last der Datenmengen zusammen. Genau an diesem Punkt stehen viele Entwickler bei der Datenbankmodellierung, wenn sie die Debatte Primary Key vs Foreign Key führen. Es geht nicht nur um technische Begriffe, sondern um das Fundament jeder relationalen Datenbank, die heute in Unternehmen weltweit eingesetzt wird. Wer diese Konzepte ignoriert, riskiert inkonsistente Datensätze, die im schlimmsten Fall zu falschen Abrechnungen oder verlorenen Kundeninformationen führen.
Ich habe in den letzten zehn Jahren unzählige SQL-Skripte gesehen, die ohne klare Strategie für diese Schlüssel erstellt wurden. Das Ergebnis war fast immer dasselbe: Langsame Abfragen und Datenleichen, die niemand mehr zuordnen konnte. Ein Primärschlüssel ist dein digitaler Fingerabdruck für jede Zeile. Er sorgt dafür, dass ein Datensatz absolut einzigartig bleibt. Der Fremdschlüssel hingegen ist das Bindeglied, das zwei Tabellen logisch miteinander verknüpft. Ohne diese Brücken hättest du nur isolierte Datensilos, die keinen Sinn ergeben. Wir schauen uns jetzt an, wie du diese Werkzeuge so einsetzt, dass deine Architektur auch nach Jahren noch sauber läuft. Für eine detailliertere Darstellung zu diesem Bereich, lesen Sie: diesen verwandten Artikel.
Das Herzstück der Tabelle und seine Funktionsweise
Jede Tabelle in einer SQL-Datenbank braucht einen Anker. Dieser Anker stellt sicher, dass man jede Information exakt ansprechen kann. Man nennt diesen Wert den Primärschlüssel. Er darf niemals doppelt vorkommen. Er darf auch niemals leer sein. Denk an deine Steuernummer beim Finanzamt. Es gibt Millionen Bürger, aber diese eine Nummer gehört nur dir. Würde das Finanzamt Namen als Identifikator nutzen, gäbe es bei jedem „Thomas Müller“ ein riesiges Problem.
In der Praxis nutzen wir oft künstliche Werte wie eine fortlaufende ID. Das ist stabil. Es ist schnell. Datenbanken lieben Zahlen. Wenn du eine Tabelle für Kunden anlegst, startest du bei 1 und zählst hoch. Diese Zahl ändert sich nie, selbst wenn der Kunde heiratet und seinen Namen ändert oder umzieht. Das ist die Stabilität, die ein Primärschlüssel bietet. Er ist der unveränderliche Fixpunkt in einem Ozean aus variablen Daten. Für umfassendere Details zu dieser Angelegenheit ist eine detaillierte Analyse bei Computer Bild verfügbar.
Warum natürliche Schlüssel oft eine Falle sind
Manche Leute schlagen vor, die E-Mail-Adresse oder die ISBN eines Buches als Primärschlüssel zu verwenden. Das klingt logisch, ist aber riskant. E-Mail-Adressen ändern sich. Verlage machen Fehler bei ISBNs. Sobald du einen Primärschlüssel ändern musst, der bereits in anderen Tabellen verwendet wird, hast du ein Problem. Der Aufwand für die Aktualisierung ist enorm. Ich empfehle daher fast immer sogenannte Surrogat-Keys. Das sind wertfreie, automatisch generierte Nummern. Sie haben keinen Bezug zur Realität außerhalb der Datenbank, was sie extrem wartungsfreundlich macht.
Die technischen Anforderungen an die Einzigartigkeit
Ein Primärschlüssel muss technisch durch einen Index unterstützt werden. Das macht die Suche nach einer bestimmten Zeile blitzschnell. Wenn du SELECT * FROM kunden WHERE kunden_id = 54321 ausführst, muss die Datenbank nicht die ganze Tabelle lesen. Sie springt dank des Indexes direkt zum Ziel. Das spart Rechenpower und Zeit. Besonders bei Millionen von Datensätzen merkst du den Unterschied sofort. Ohne diesen Index würde dein Server bei jeder kleinen Anfrage ins Schwitzen kommen.
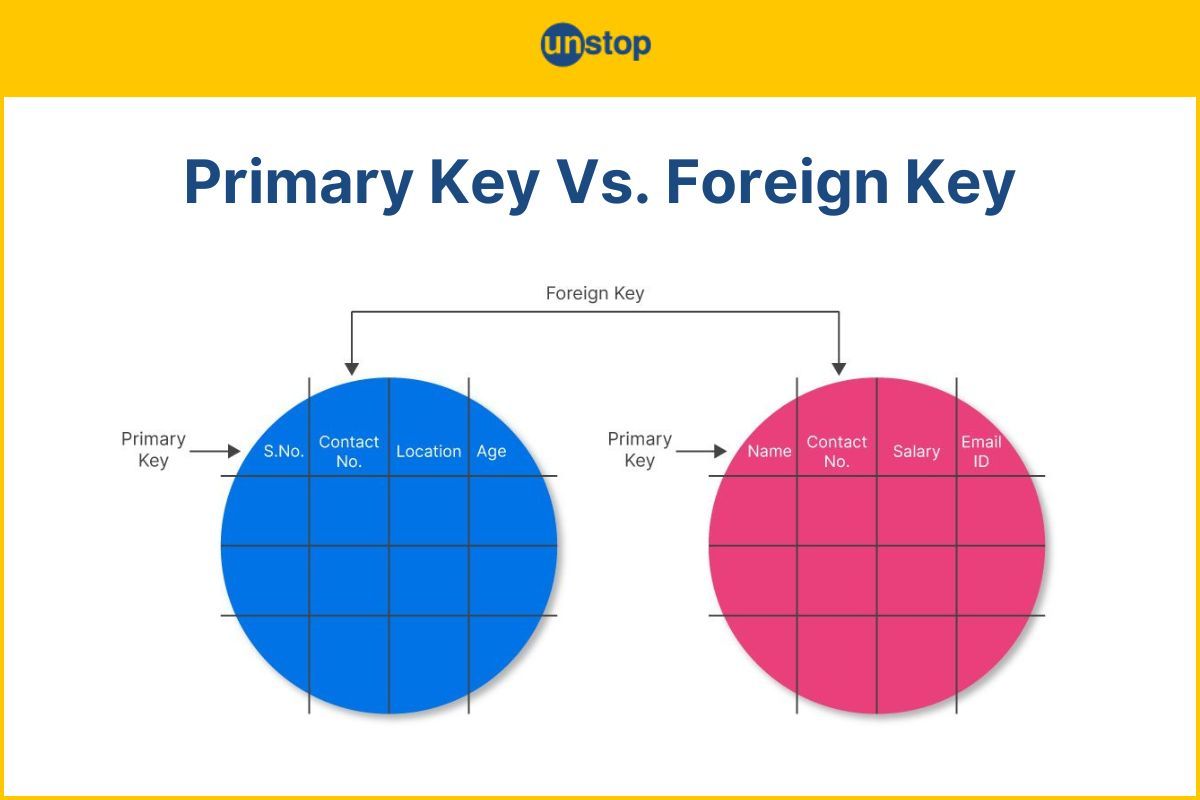
Die Brücke zwischen den Welten mit Primary Key vs Foreign Key schlagen
Wenn wir über die Beziehung zwischen Daten sprechen, kommen wir nicht um das Konzept der Verknüpfung herum. Eine relationale Datenbank heißt so, weil sie Relationen, also Beziehungen, abbildet. Hier kommt der Fremdschlüssel ins Spiel. Er ist im Grunde ein Primärschlüssel aus einer anderen Tabelle, der in einer neuen Tabelle gespeichert wird, um eine Verbindung herzustellen.
Stell dir eine Bestellung vor. In der Tabelle „Bestellungen“ steht eine Spalte „KundenID“. Diese ID verweist direkt auf den Primärschlüssel in der Tabelle „Kunden“. So wissen wir genau, wer was gekauft hat, ohne den Namen des Kunden in jeder Bestellung neu tippen zu müssen. Das spart Platz. Das verhindert Fehler. Wenn sich die Adresse des Kunden ändert, korrigieren wir sie an einer einzigen Stelle – in der Kundentabelle. Alle Bestellungen bleiben automatisch mit dem richtigen Profil verknüpft. Das ist das Prinzip der Normalisierung.
Referenzielle Integrität als Schutzschild
Ein Fremdschlüssel ist nicht nur ein passives Feld. Er ist ein aktiver Wächter. Das Datenbanksystem prüft ständig, ob die Beziehung noch stimmt. Wenn du versuchst, eine Bestellung für einen Kunden anzulegen, den es gar nicht gibt, wird die Datenbank den Befehl ablehnen. Das ist die referenzielle Integrität. Sie verhindert, dass du „Waisenkinder“ in deinen Daten erzeugst – also Datensätze, die ins Leere laufen.
Das ist besonders wichtig, wenn Daten gelöscht werden. Was passiert, wenn ein Kunde gelöscht wird, der noch offene Bestellungen hat? Ein gut konfigurierter Fremdschlüssel gibt dir hier Optionen. Du kannst das Löschen blockieren (RESTRICT). Du kannst die Bestellungen automatisch mitlöschen (CASCADE). Oder du setzt die Verknüpfung auf leer (SET NULL). Jede dieser Entscheidungen hat massive Auswirkungen auf die Geschäftslogik deines Systems. In der Welt der relationalen Datenbanken ist dies das wichtigste Sicherheitsnetz, das du hast.
Performance und Indizierung von Verknüpfungen
Fremdschlüssel sollten fast immer einen eigenen Index haben. Warum? Weil du sehr oft Tabellen miteinander verbinden wirst (JOIN). Wenn du wissen willst, welche Produkte Kunde Meier gekauft hat, muss die Datenbank die IDs abgleichen. Ohne Index auf der Fremdschlüssel-Spalte wird dieser Abgleich extrem langsam. Ich habe Systeme gesehen, bei denen ein einfacher Bericht Minuten dauerte, nur weil die Indizes auf den Fremdschlüsseln fehlten. Ein kleiner Befehl im SQL-Skript hätte das verhindert.
Strategien für komplexe Datenmodelle
Manchmal reicht ein einzelner Wert nicht aus, um eine Zeile zu identifizieren. In solchen Fällen greifen wir zu zusammengesetzten Schlüsseln. Das bedeutet, dass zwei oder mehr Spalten zusammen den Primärschlüssel bilden. Das sieht man oft in Verknüpfungstabellen für viele-zu-viele-Beziehungen. Ein Beispiel: Ein Student besucht mehrere Kurse, und ein Kurs hat viele Studenten. In der Tabelle „Belegungen“ bilden die „StudentenID“ und die „KursID“ zusammen den Schlüssel. Kein Student kann denselben Kurs zweimal gleichzeitig belegen.
Diese Methode hat jedoch Tücken. Zusammengesetzte Schlüssel machen Fremdschlüssel-Beziehungen komplizierter. Die verknüpfte Tabelle muss dann nämlich ebenfalls beide Spalten speichern, um die Verbindung aufrechtzuerhalten. Das bläht das Schema auf. In meiner Arbeit versuche ich das zu vermeiden. Eine einfache, eindeutige ID ist fast immer die sauberere Lösung, auch wenn die Logik dahinter etwas abstrakter wirkt.
Datentypen und Speicherplatz optimieren
Wähle deine Datentypen klug. Ein Primärschlüssel vom Typ BIGINT bietet Platz für fast unendlich viele Datensätze. Ein einfacher INT reicht bis etwa 2,1 Milliarden. Für die meisten Projekte ist das genug. Aber wenn du ein System wie Twitter oder Instagram baust, sind 2 Milliarden schnell erreicht. Dann brauchst du BIGINT. Achte darauf, dass der Datentyp des Fremdschlüssels exakt dem des Primärschlüssels entspricht. Wenn der Primärschlüssel ein Vorzeichen-behafteter Integer ist, muss der Fremdschlüssel das auch sein. Sonst meckert die Datenbank oder die Performance leidet unter der internen Konvertierung.
UUIDs gegen klassische Integer
In modernen Cloud-Systemen sieht man oft UUIDs (Universally Unique Identifiers) als Schlüssel. Das sind lange Ketten aus Zahlen und Buchstaben wie 550e8400-e29b-41d4-a716-446655440000. Der Vorteil ist, dass du diese IDs generieren kannst, ohne die Datenbank zu fragen. Das ist super für verteilte Systeme. Der Nachteil? Sie fressen mehr Speicherplatz. Sie sind langsamer beim Sortieren. Für ein klassisches Webprojekt mit einer zentralen Datenbank wie MySQL oder PostgreSQL fährst du mit Integern meistens besser. Es sei denn, du musst Daten aus verschiedenen Quellen mergen, ohne dass die IDs kollidieren.
Praktische Anwendung in SQL
Schauen wir uns an, wie das Ganze im Code aussieht. Es ist kein Hexenwerk, aber die Syntax muss sitzen. Hier ist ein Beispiel für die Erstellung zweier verknüpfter Tabellen in Standard-SQL. Wir erstellen eine Tabelle für Autoren und eine für deren Bücher.
CREATE TABLE Autoren (
AutorID INT PRIMARY KEY,
Name VARCHAR(100)
);
CREATE TABLE Buecher (
BuchID INT PRIMARY KEY,
Titel VARCHAR(200),
AutorID INT,
FOREIGN KEY (AutorID) REFERENCES Autoren(AutorID)
);
Dieses einfache Beispiel zeigt den Kern der Sache. Das Feld AutorID in der Tabelle Buecher sorgt dafür, dass kein Buch existieren kann, ohne einem gültigen Autor zugeordnet zu sein. Wenn du versuchst, ein Buch für den Autor mit der ID 99 anzulegen, dieser Autor aber nicht existiert, wird die Datenbank den Dienst quittieren. Das ist genau das, was wir wollen. Wir erzwingen Sauberkeit auf der untersten Ebene der Software.
Häufige Fehler bei der Implementierung
Ein klassischer Fehler ist das Vergessen von „ON DELETE CASCADE“. Stell dir vor, du hast ein Forum. Wenn ein Nutzer sein Konto löscht, was passiert mit seinen Beiträgen? Wenn du den Fremdschlüssel ohne spezielle Anweisung anlegst, wird die Datenbank das Löschen des Nutzers verhindern, solange noch Beiträge da sind. Das ist nervig für den User. Mit ON DELETE CASCADE sagst du der Datenbank: Wenn der Nutzer geht, lösche bitte auch all seinen Content automatisch mit. Das hält die Datenbank sauber. Aber Vorsicht: Ein falscher Klick und ganze Datenberge verschwinden im digitalen Nirwana.
Ein anderer Fehler ist die mangelnde Dokumentation. Wer später an deinem Code arbeitet, muss verstehen, warum welche Beziehung existiert. Nutze Kommentare im SQL-Code. Nutze Tools wie ER-Diagramme, um die Struktur visuell darzustellen. Ein Bild sagt hier wirklich mehr als tausend Zeilen Code. In Deutschland legen wir Wert auf Präzision, und das sollte sich in deiner Schema-Dokumentation widerspiegeln.
Die Rolle von Schlüsseln in NoSQL-Datenbanken
Viele Leute fragen mich, ob man sich über Primary Key vs Foreign Key überhaupt noch Gedanken machen muss, wenn man MongoDB oder andere NoSQL-Systeme nutzt. Die Antwort ist ein klares Ja, aber die Herangehensweise ändert sich. In einer Dokument-Datenbank speicherst du oft zusammengehörige Daten in einem einzigen Dokument. Anstatt einer Kunden- und einer Bestelltabelle hast du ein Kundendokument, in dem die Bestellungen direkt als Liste drinstehen.
Das eliminiert den Fremdschlüssel im klassischen Sinne, bringt aber neue Probleme. Wenn sich ein Produktname ändert, musst du ihn in tausenden Dokumenten aktualisieren. Das ist ineffizient. Deshalb nutzen erfahrene Entwickler auch in NoSQL oft Referenzen, die wie Fremdschlüssel funktionieren. Man speichert nur die ID des Produkts. Die Logik der Verknüpfung wandert dann von der Datenbank-Engine in deinen Anwendungscode. Das macht den Code komplexer, gibt dir aber mehr Flexibilität bei der Skalierung. Letztlich entkommt man den Grundprinzipien der Datenstrukturierung nie.
Skalierbarkeit und Sharding
Wenn deine Datenbank so groß wird, dass sie auf mehrere Server aufgeteilt werden muss (Sharding), werden Fremdschlüssel zu einer echten Herausforderung. Es ist technisch extrem schwierig, die referenzielle Integrität über Servergrenzen hinweg zu garantieren. Große Player wie Facebook oder Amazon verzichten an manchen Stellen bewusst auf harte Fremdschlüssel-Constraints, um die Geschwindigkeit zu erhöhen. Sie prüfen die Konsistenz stattdessen asynchron im Hintergrund. Das ist aber die Champions League der Softwareentwicklung. Für 99 % aller Projekte sind klassische Constraints der sicherste Weg.
Die Bedeutung für Data Analytics
Auch in Data Warehouses oder bei der Arbeit mit PowerBI spielen diese Schlüssel eine tragende Rolle. Wenn du Daten aus verschiedenen Quellen zusammenführst, brauchst du eindeutige Identifier, um die Sätze zu matchen. Wenn dein CRM-System eine andere ID für einen Kunden nutzt als dein ERP-System, hast du ein Problem. Hier helfen Mapping-Tabellen, die im Grunde nur aus Fremdschlüsseln bestehen, die verschiedene Welten verbinden. Wer hier von Anfang an sauber arbeitet, spart den Datenanalysten Wochen an Arbeit beim Bereinigen der Datensätze.
Praktische Schritte für dein nächstes Projekt
Wenn du jetzt vor deinem nächsten Datenbank-Entwurf sitzt, geh strukturiert vor. Theorie ist gut, aber die Umsetzung entscheidet über Erfolg oder Misserfolg. Hier sind die Schritte, die ich bei jedem neuen Schema befolge:
- Definiere für absolut jede Tabelle einen Primärschlüssel. Nutze dafür am besten eine einfache
idvom TypINToderBIGINTmitAUTO_INCREMENT. Das nimmt dir das Denken ab und ist extrem performant. - Identifiziere die Beziehungen zwischen deinen Datenobjekten. Wer gehört zu wem? Zeichne das auf Papier oder mit einem Tool wie Draw.io auf.
- Lege Fremdschlüssel für jede dieser Beziehungen an. Benenne die Spalten konsistent, zum Beispiel
user_id, wenn sie auf die Tabelleusersverweist. Konsistenz ist dein bester Freund bei der Fehlersuche. - Entscheide dich für eine Lösch-Strategie. In den meisten Fällen ist
ON DELETE SET NULLoderON DELETE RESTRICTsicherer alsCASCADE. Lösche Daten nur dann automatisch, wenn du dir absolut sicher bist, dass sie ohne das Eltern-Objekt wertlos sind. - Setze Indizes auf deine Fremdschlüssel-Spalten. Das ist kein optionaler Schritt. Mach es einfach immer. Dein zukünftiges Ich wird dir danken, wenn die Datenbank bei der ersten großen Last nicht in die Knie geht.
- Teste dein Schema mit echten Grenzfällen. Was passiert, wenn ein Feld leer bleibt? Was passiert bei einer Dublette? Nutze SQL-Constraints wie
UNIQUEzusätzlich zum Primärschlüssel, wenn bestimmte fachliche Werte (wie eine Personalnummer) ebenfalls einzigartig sein müssen.
Datenbankdesign ist ein Handwerk. Es braucht Übung und ein Auge für Details. Aber wenn du die Grundlagen von Primär- und Fremdschlüsseln beherrschst, hast du das wichtigste Werkzeug bereits im Kasten. Es sorgt für Ordnung im digitalen Lagerhaus und stellt sicher, dass deine Anwendung auch dann noch stabil läuft, wenn die Nutzerzahlen explodieren. Denk immer daran: Daten sind das wertvollste Gut eines Unternehmens. Behandle sie mit dem Respekt, den sie verdienen, indem du ihnen eine solide Struktur gibst. Jede Minute, die du heute in ein sauberes Schema investierst, spart dir später Stunden bei der Fehlersuche. Fang klein an, bleib konsistent und lass die Datenbank die harte Arbeit der Validierung für dich erledigen. Das ist der Weg zu professioneller Softwareentwicklung.



