Jeder Entwickler kennt diesen Moment der totalen Orientierungslosigkeit nach dem Einloggen in einen fremden Server. Du starrst auf das schwarze Terminal, die Verbindung steht, aber du hast keinen blassen Schimmer, was sich in diesem digitalen Keller eigentlich verbirgt. Wer Ordnung in das Chaos bringen will, braucht die richtigen Befehle, und genau hier kommt das Thema MySQL How To List Tables ins Spiel, um dir den Überblick über deine Datenstrukturen zurückzugeben. Es geht nicht nur darum, eine Liste von Namen auszuspucken. Es geht darum, die Architektur einer Anwendung zu verstehen, bevor du die erste Zeile Code änderst.
Den Durchblick behalten mit MySQL How To List Tables
Wenn du dich fragst, wie du schnell und schmerzlos alle Tabellen in deiner aktuellen Datenbank anzeigen lassen kannst, ist der Klassiker ungeschlagen. Der Standardbefehl lautet schlicht SHOW TABLES;. Das ist das Brot-und-Butter-Geschäft für jeden, der mit relationalen Datenbanken arbeitet. Ich habe schon unzählige Male erlebt, dass Leute versuchen, komplizierte Abfragen über das Informationsschema zu schreiben, obwohl die Lösung so nah liegt.
Warum Einfachheit gewinnt
Manchmal vergisst man vor lauter Komplexität die Basics. Du tippst den Befehl ein und sofort listet das System alles auf, was in der aktiven Datenbank existiert. Das ist besonders hilfreich, wenn du mit Legacy-Systemen arbeitest, bei denen die Dokumentation seit Jahren im Schrank verstaubt. Du siehst sofort, ob Präfixe wie wp_ oder drupal_ verwendet werden. Das hilft dir massiv dabei, die Umgebung einzuordnen.
Einschränkungen der Standardanzeige
Man muss aber ehrlich sein: SHOW TABLES ist manchmal ein bisschen zu simpel. Wenn du hunderte Tabellen hast, scrollst du dich zu Tode. Hier hilft die LIKE-Klausel. Wenn du nur wissen willst, welche Tabellen mit „user“ anfangen, schreibst du SHOW TABLES LIKE 'user%';. Das spart Zeit und Nerven. Ich nutze das ständig, wenn ich in riesigen E-Commerce-Datenbanken nach den spezifischen Bestelldaten suche, ohne von tausenden Metadaten-Tabellen erschlagen zu werden.
Die Macht der Metadaten und versteckte Strukturen
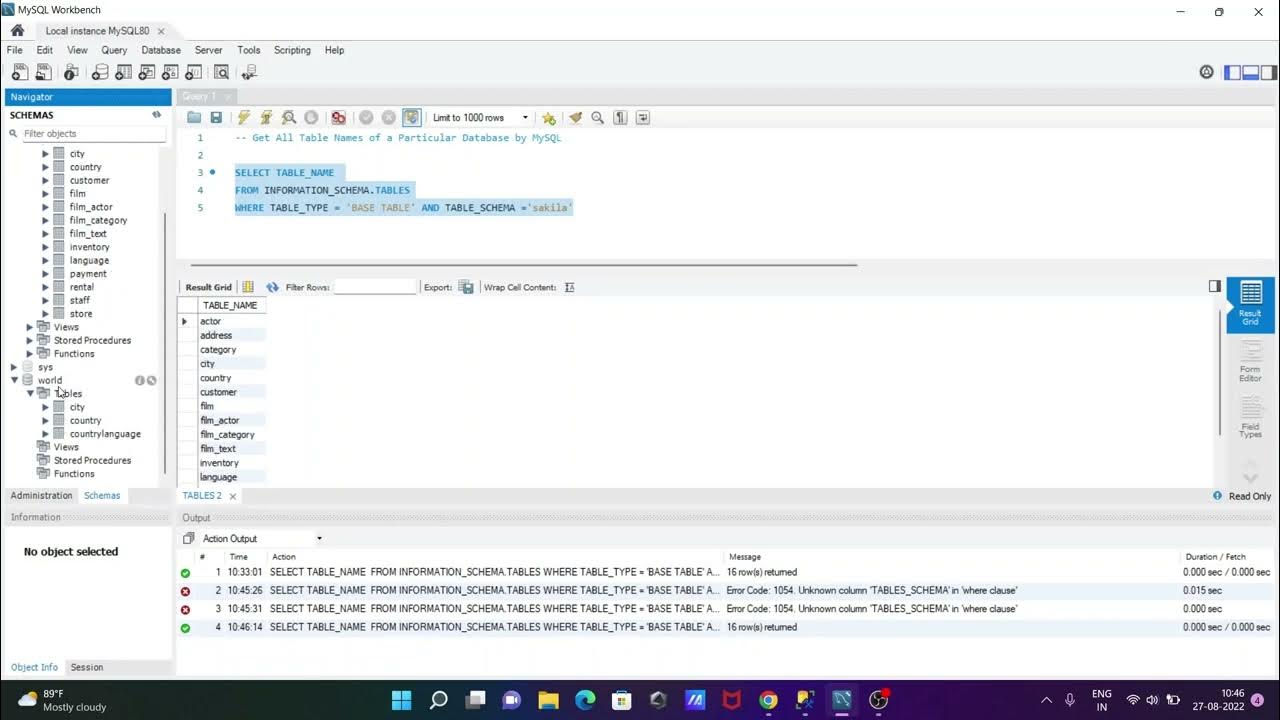
Wer tiefer graben will, kommt an der Tabelle information_schema.tables nicht vorbei. Das ist quasi das Gehirn von MySQL. Hier liegen Informationen, von denen der normale SHOW-Befehl nur träumt. Ich rede von Speichergrößen, der Anzahl der Zeilen und dem Zeitpunkt der letzten Aktualisierung. Das ist echtes Insiderwissen für Admins.
Abfragen über das Information Schema
Stell dir vor, du musst herausfinden, welche deiner Tabellen den meisten Platz auf der Festplatte frisst. Das findest du nicht mit einem einfachen Auflistungsbefehl heraus. Du musst das Informationsschema anzapfen. Eine Abfrage auf information_schema.tables erlaubt es dir, nach der Datengröße zu sortieren. Das ist Gold wert, wenn der Serverplatz knapp wird und du die Übeltäter identifizieren musst. Du kannst gezielt nach Tabellentypen filtern, etwa um nur die permanenten Basistabellen und keine temporären Ansichten zu sehen.
Die Rolle der Storage Engines
Ein Punkt, den viele unterschätzen, ist die verwendete Engine. Früher war MyISAM der Standard, heute ist es fast immer InnoDB. Wenn du wissen willst, welche Tabelle welche Engine nutzt, kannst du das direkt mit SHOW TABLE STATUS abfragen. Das ist kein unnützes Wissen. Wenn du Transaktionen brauchst, aber eine alte Tabelle noch auf MyISAM läuft, knallt es in deiner Anwendung. Ich prüfe das grundsätzlich als Erstes, wenn ich eine Datenbank übernehme. Auf der offiziellen Seite von Oracle findest du detaillierte Dokumentation zu den Unterschieden dieser Engines, was für die Performance-Optimierung extrem wichtig ist.
Filtern und Sortieren wie ein Profi
Manchmal reicht eine einfache Liste einfach nicht aus. In Projekten mit komplexen Datenmodellen, wie man sie oft in Enterprise-Lösungen findet, gibt es oft Namenskonventionen, die man ausnutzen kann.
Arbeiten mit Wildcards
Die Verwendung von Platzhaltern ist dein bester Freund. Das Prozentzeichen % steht für beliebig viele Zeichen, der Unterstrich _ für genau ein Zeichen. Das ist Standard-SQL-Wissen, aber in der Hitze des Gefechts wird es oft ignoriert. Wenn du MySQL How To List Tables effektiv anwendest, nutzt du diese Muster, um deine Suche einzugrenzen. Ich habe schon Projekte gesehen, die über 4000 Tabellen hatten. Ohne gezielte Filterung bist du dort völlig aufgeschmissen.
Tabellen aus verschiedenen Datenbanken anzeigen
Du musst nicht zwingend die Datenbank mit USE wechseln, um die Tabellen zu sehen. Du kannst SHOW TABLES FROM datenbankname; verwenden. Das ist super praktisch für Skripte oder wenn du nur mal kurz über den Zaun zum Nachbarn schauen willst. Es spart diesen einen nervigen Zwischenschritt. Wer viel auf der Kommandozeile arbeitet, weiß diese kleinen Zeitfresser-Eliminierungen zu schätzen.
Tools und grafische Oberflächen vs. Terminal
Ich bin ein großer Fan des Terminals. Es ist schnell, es ist überall verfügbar und es lügt nicht. Aber ich verstehe jeden, der lieber eine Maus schubst. Tools wie PHPMyAdmin oder MySQL Workbench machen das Auflisten von Tabellen natürlich per Klick möglich.
Die Gefahr der Bequemlichkeit
Grafische Tools verstecken oft die Komplexität. Du siehst eine Liste im Seitenmenü und denkst, alles ist schick. Aber was, wenn die Verbindung langsam ist? Was, wenn das Tool die Ansicht puffert und du neue Tabellen gar nicht siehst? Ich habe Entwickler gesehen, die verzweifelt sind, weil ihre Migrationen angeblich nicht funktionierten, nur weil sie vergessen hatten, in ihrer GUI auf „Refresh“ zu klicken. Auf dem Terminal passiert dir das nicht. Ein Befehl, ein aktuelles Ergebnis. Wer professionell arbeitet, sollte die CLI-Befehle im Schlaf beherrschen.
Automatisierung durch Skripte
Wenn du Backups planst oder Daten exportieren willst, musst du die Tabellenliste oft automatisiert verarbeiten. Ein Bash-Skript, das die Ausgabe von MySQL einliest, ist eine Standardaufgabe. Hier zeigt sich die wahre Stärke der textbasierten Ausgabe. Du kannst das Ergebnis direkt in eine Schleife schieben und Operationen für jede einzelne Tabelle ausführen. Das ist Effizienz, die keine GUI der Welt bieten kann. In der deutschen Entwickler-Community wird oft über Heise Online diskutiert, wie man solche Workflows am besten absichert, besonders wenn es um sensible Daten geht.
Häufige Fehler und wie du sie vermeidest
Es gibt ein paar Stolperfallen, die mir immer wieder begegnen. Der Klassiker sind fehlende Berechtigungen. Wenn dein Benutzer keine SELECT- oder SHOW VIEW-Rechte hat, wird die Liste leer sein oder eine Fehlermeldung werfen. Das heißt aber nicht, dass keine Tabellen da sind. Es heißt nur, dass du sie nicht sehen darfst.
Berechtigungsprobleme lösen
Wenn du SHOW TABLES ausführst und nichts zurückkommt, obwohl du weißt, dass die Datenbank prall gefüllt ist, check deine Privilegien. Ein SHOW GRANTS FOR CURRENT_USER; bringt Licht ins Dunkel. Oft hat der Admin vergessen, die nötigen Leserechte auf die Tabellenebene zu vergeben. Das passiert besonders oft in Shared-Hosting-Umgebungen, wo die Sicherheitseinstellungen extrem strikt sind.
Verwirrung durch Views
Views sehen in der Liste oft aus wie normale Tabellen. Das kann extrem verwirrend sein, wenn du versuchst, Daten direkt zu ändern oder die Struktur zu manipulieren. Mit SHOW FULL TABLES; kannst du dir eine zusätzliche Spalte anzeigen lassen, die dir verrät, ob es sich um eine BASE TABLE oder eine VIEW handelt. Ich mache das zur Routine, um keine bösen Überraschungen zu erleben, wenn ich ein fremdes Schema analysiere. Views sind toll, aber man muss wissen, womit man es zu tun hat.
Performance-Aspekte bei riesigen Instanzen
Man glaubt es kaum, aber selbst das Auflisten von Tabellen kann bei extrem großen Systemen die Performance beeinflussen. Wenn du zehntausende Tabellen in einem einzigen Schema hast – was per se schon ein schlechtes Design ist, aber vorkommt – muss MySQL im Dateisystem nachschauen oder den Dictionary-Cache bemühen.
Der Einfluss von Dateisystem-Limits
Unter Linux gibt es Limits für die Anzahl der Dateien in einem Verzeichnis. Da MySQL (je nach Engine) pro Tabelle eine oder mehrere Dateien anlegt, kann das Auflisten bei riesigen Mengen zäh werden. Ich habe Systeme erlebt, bei denen SHOW TABLES mehrere Sekunden dauerte. Das ist ein Warnsignal. Es deutet darauf hin, dass die Datenbank-Architektur überarbeitet werden muss. In solchen Fällen ist es besser, die Metadaten direkt aus dem information_schema abzufragen und dabei sehr spezifische Filter zu setzen.
Caching und das Data Dictionary
Seit MySQL 8.0 gibt es das neue Data Dictionary. Das hat die Geschwindigkeit von Metadaten-Abfragen massiv verbessert. Früher musste der Server oft physisch auf die .frm-Dateien zugreifen, was bei langsamen Festplatten eine Qual war. Jetzt liegen diese Infos in spezialisierten Tabellen, was den Zugriff beschleunigt. Das ist ein riesiger Vorteil für moderne Anwendungen, die auf schnelles Feedback angewiesen sind. Wer noch auf 5.7 festsitzt, sollte allein deswegen über ein Upgrade nachdenken. Details zu den Sicherheitsaspekten solcher Upgrades findet man beim Bundesamt für Sicherheit in der Informationstechnik, da veraltete Datenbankversionen oft Sicherheitslücken aufweisen.
Praktische Beispiele für den Alltag
Graue Theorie ist langweilig. Schauen wir uns an, was du wirklich im Terminal tippst. Ein typisches Szenario ist die Suche nach Tabellen, die keine Daten enthalten. Das ist perfekt, um aufzuräumen. Du fragst das Informationsschema ab und filterst nach TABLE_ROWS = 0. So findest du sofort Leichen im Keller, die vielleicht bei einem missglückten Importversuch übrig geblieben sind.
Tabellen nach Größe sortieren
Wenn die Festplatte glüht, hilft dieser Ansatz: Du berechnest die Summe aus data_length und index_length im Informationsschema. Dann rechnest du das Ganze in Megabyte um, indem du durch 1024 mal 1024 teilst. Das Ergebnis sortierst du absteigend. Jetzt hast du eine Liste deiner schwersten Tabellen. Ich mache das einmal im Monat bei meinen Produktionsservern, um Trends beim Datenwachstum zu erkennen. Wenn die Log-Tabelle plötzlich 10 GB groß ist, weiß ich, dass irgendwo ein Debug-Modus Amok läuft.
Prüfung von Zeichensätzen
Ein weiteres Problem sind unterschiedliche Kollationen. Wenn du Tabellen mit utf8mb4 und andere mit latin1 mischt, gibt es beim Joinen Tränen. Du kannst dir über das Informationsschema eine Liste aller Tabellen und ihrer Standard-Kollation ziehen. So stellst du sicher, dass alles konsistent ist, bevor du die Anwendung live schaltest. Inkonsistente Zeichensätze sind der Grund Nummer eins für kaputte Umlaute in deutschen Texten.
Warum SQL-Kenntnisse für Admins alternativlos sind
Egal wie gut die KI-Tools oder No-Code-Plattformen werden, die Basis bleibt SQL. Wer versteht, wie man unter die Haube schaut, kann Probleme lösen, an denen andere verzweifeln. Das Auflisten von Tabellen ist dabei nur der erste Schritt einer langen Reise. Es ist die Landkarte, auf der du deine Route planst. Ohne diese Karte läufst du blind durch den Wald.
Die Bedeutung von Standards
MySQL hält sich weitgehend an SQL-Standards, aber jeder Hersteller kocht sein eigenes Süppchen. Bei PostgreSQL heißt der Befehl anders, bei SQL Server auch. Aber das Konzept der Metadaten-Tabellen ist universell. Wenn du einmal verstanden hast, wie MySQL das macht, fällt dir der Wechsel zu anderen Systemen leicht. Du suchst dann einfach nach dem Äquivalent zum Informationsschema. Das ist echtes Transferwissen, das deinen Wert als Entwickler steigert.
Zukunftssichere Datenbankpflege
Datenbanken werden nicht kleiner. Die Anforderungen an Logging, Analyse und Datenspeicherung steigen ständig. Deshalb ist es so wichtig, die Werkzeuge zur Strukturprüfung zu beherrschen. Es wird immer Situationen geben, in denen du schnell wissen musst, was in deiner Instanz los ist. Ob beim Debuggen, beim Audit oder bei der Vorbereitung einer Migration – die Fähigkeit, die Struktur deiner Daten in Sekunden abzurufen, ist eine Kernkompetenz.
Nächste Schritte für deine Datenbank-Praxis
Jetzt hast du eine Menge über das Auflisten von Tabellen gelernt. Aber Wissen ohne Anwendung ist wertlos. Hier sind die nächsten Schritte, die du heute noch tun solltest, um deine Skills zu festigen:
- Logge dich in deine lokale Testumgebung ein und probiere
SHOW FULL TABLESaus, um den Unterschied zwischen Views und Basistabellen mit eigenen Augen zu sehen. - Schreibe eine Abfrage auf
information_schema.tables, die dir nur die Tabellennamen und die Anzahl der Zeilen ausgibt. Das ist eine super Übung für den Umgang mit Metadaten. - Überprüfe die Storage Engines deiner wichtigsten Tabellen. Wenn dort noch MyISAM auftaucht, erstelle einen Plan für die Migration zu InnoDB, um von besserer Crash-Resistenz zu profitieren.
- Experimentiere mit Wildcards. Suche gezielt nach Tabellenmustern in einer großen Datenbank, um ein Gefühl für die Geschwindigkeit der
LIKE-Klausel zu bekommen.
Wer diese Basics beherrscht, wird in Stresssituationen deutlich ruhiger bleiben. Datenbankadministration ist zu einem großen Teil das Wissen darüber, wo man suchen muss. Mit den richtigen Befehlen im Gepäck bist du bestens gerüstet. Geh jetzt an dein Terminal und probier es aus. Es gibt keine bessere Art zu lernen als durch direktes Machen. Viel Erfolg beim Strukturieren deiner Datenwelten.



