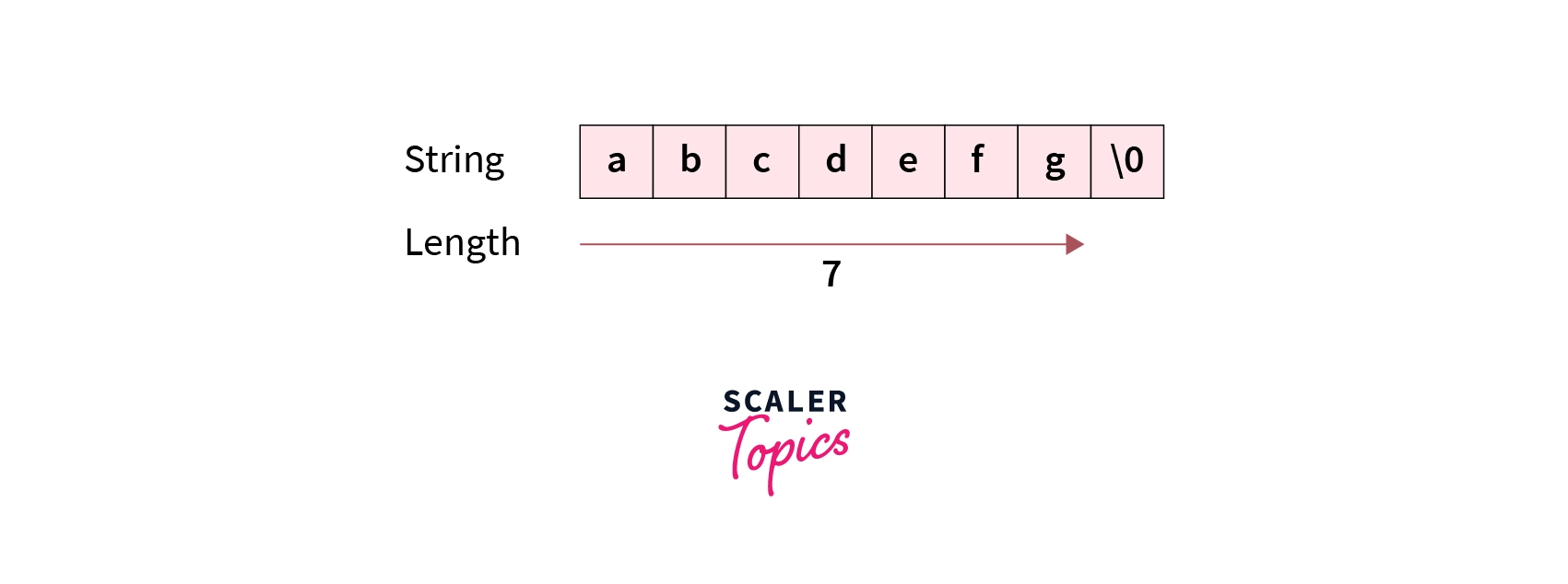
Die Vorstellung, dass ein Computer weiß, wie lang ein Text ist, gehört zu den hartnäckigsten Irrtümern der modernen Softwareentwicklung. Wir tippen ein Wort in eine Tastatur und erwarten, dass die Maschine dessen Ausdehnung im Speicher ebenso intuitiv erfasst wie wir die Anzahl der Buchstaben auf einem Blatt Papier. In der Programmiersprache C existiert diese Intuition jedoch nicht. Es gibt keinen eingebauten Zähler, kein Metadaten-Feld und keine magische Eigenschaft, die dem System verrät, wann eine Information endet. Wer die Len Of String In C bestimmen will, begibt sich auf eine archaische Spurensuche, die eher einer Expedition durch einen dunklen Tunnel gleicht als einem präzisen Messvorgang. Man tastet sich so lange voran, bis man gegen eine Wand stößt. Diese Wand ist das Null-Byte, ein unsichtbares Zeichen mit dem Wert null, das das Ende markiert. Fehlt dieses Zeichen durch einen winzigen Fehler im Code, rennt das Programm metaphorisch gesehen ungebremst weiter in den Abgrund des Arbeitsspeichers. Es liest Passwörter aus, stürzt ab oder öffnet Hintertüren für Angreifer. Die Länge eines Strings ist in dieser Welt keine statische Eigenschaft, sondern das Ergebnis einer riskanten Wanderung.
Die gefährliche Illusion der Len Of String In C
Die meisten Programmierer lernen früh, dass sie die Funktion strlen verwenden sollen, um die Größe eines Textes zu ermitteln. Was dabei oft übersehen wird, ist die fundamentale Ineffizienz und Unsicherheit, die hinter diesem Befehl steckt. Jedes Mal, wenn man diese Funktion aufruft, muss der Prozessor den gesamten Text von vorne bis hinten durchkämmen. Bei einem Text von einer Million Zeichen bedeutet das eine Million einzelne Vergleiche, nur um eine Information zu erhalten, die moderne Sprachen wie Rust oder Python einfach in einem kleinen Header mitschleppen. Es ist eine architektonische Entscheidung aus den 1970er Jahren, die wir bis heute mitschleppen. Damals war Speicherplatz teurer als Gold und jedes Byte, das man für einen Längen-Zähler hätte opfern müssen, galt als Verschwendung. Heute bezahlen wir diesen Geiz mit Sicherheitslücken, die ganze Infrastrukturen lahmlegen können. Das Problem ist nun mal so, dass C dem Entwickler blind vertraut. Wenn du sagst, dass dort ein Text liegt, dann glaubt die Sprache dir das, bis das Gegenteil bewiesen ist – meistens durch einen spektakulären Systemabsturz.
Ich habe oft erlebt, wie junge Entwickler versuchen, die Performance ihrer Anwendungen zu optimieren, während sie gleichzeitig in jeder Schleife die Länge eines Strings neu berechnen lassen. Sie merken nicht, dass sie damit die Rechenzeit quadratisch in die Höhe treiben. Ein Algorithmus, der eigentlich schnell sein sollte, wird zur Schnecke, weil das System immer wieder denselben dunklen Tunnel abschreitet. Die Fixierung auf diese eine Standardlösung blendet aus, dass wir es mit einem Konzept zu tun haben, das für die heutige vernetzte Welt eigentlich ungeeignet ist. Wir hantieren mit Werkzeugen, die für isolierte Mainframes gebaut wurden, und wundern uns, warum das Internet der Dinge so anfällig für Pufferüberläufe ist. Ein Pufferüberlauf passiert genau dann, wenn die Annahme über die Länge nicht mit der Realität im Speicher übereinstimmt. Es ist die Diskrepanz zwischen dem, was wir glauben zu messen, und dem, was tatsächlich physisch vorhanden ist.
Warum die Len Of String In C ein Sicherheitsrisiko bleibt
Es gibt Skeptiker, die behaupten, dass ein erfahrener Programmierer diese Gefahren im Griff hat. Sie argumentieren, dass man nur diszipliniert genug sein muss, um Puffergrenzen zu prüfen und das Null-Byte niemals zu vergessen. Doch die Geschichte der Informatik widerlegt diese Arroganz. Selbst die fähigsten Ingenieure bei Firmen wie Google oder Microsoft machen Fehler. Die Heartbleed-Lücke in OpenSSL war im Kern nichts anderes als ein Missverständnis darüber, wie viel Daten aus einem Speicherbereich gelesen werden durften. Wenn ein System darauf basiert, dass man ständig manuell nachzählt, wie weit man gehen darf, ist menschliches Versagen vorprogrammiert. Disziplin ist keine skalierbare Sicherheitsstrategie. Wir brauchen Strukturen, die Fehler unmöglich machen, anstatt darauf zu hoffen, dass der Mensch keine macht. In C ist die Länge eines Strings jedoch untrennbar mit dem Inhalt verwoben. Man kann das eine nicht ohne das andere validieren.
Die Anatomie des Scheiterns im Speicher
Wenn wir uns die physische Ebene ansehen, wird das Dilemma noch deutlicher. Ein String in C ist lediglich ein Zeiger auf eine Adresse im RAM. Ab dieser Adresse folgen Bytes. Das System hat keine Ahnung, ob diese Bytes zu einem Namen, einem Bild oder einem ausführbaren Programmcode gehören. Erst das Erreichen des Null-Bytes stoppt den Lesevorgang. Wenn ein Angreifer es schafft, dieses Null-Byte zu überschreiben, kann er das Programm dazu bringen, sensible Daten preiszugeben, die zufällig direkt dahinter im Speicher liegen. Das ist kein theoretisches Szenario, sondern der Alltag der Cybersicherheit. Die Abhängigkeit von einem einzelnen Endmarker ist ein architektonischer Sündenfall. Wir bauen Wolkenkratzer auf einem Fundament, das nur aus der Hoffnung besteht, dass niemand die Markierung am Ende des Bauplatzes verschiebt. Man kann es drehen und wenden wie man will: Das Design der Zeichenketten in C ist eine Einladung zum Chaos.
Die Arroganz der manuellen Verwaltung
Ein weiteres Argument der C-Verteidiger ist die volle Kontrolle über die Hardware. Man sagt, dass nur durch diese rohe Form der Speicherverwaltung die maximale Geschwindigkeit erreicht werden kann. Das mag für spezialisierte Treiber oder eingebettete Systeme stimmen, bei denen jedes Mikrowatt zählt. Doch für den Großteil der Software, die wir täglich nutzen, ist dieser Gewinn an Geschwindigkeit vernachlässigbar im Vergleich zu den Kosten für Sicherheitsupdates und Fehlersuche. Die Kontrolle, die man zu haben glaubt, ist oft nur eine Illusion. In modernen Multicore-Systemen und komplexen Speicherhierarchien ist das manuelle Hantieren mit Zeigern und Längenmarkierungen ein Spiel mit dem Feuer. Wir optimieren an der falschen Stelle. Wir sparen ein paar Byte für einen Zähler ein und riskieren dafür die Integrität des gesamten Systems.
Die Rückkehr zur Vernunft in der Softwarearchitektur
Es gibt einen Grund, warum moderne Sprachen wie Zig oder Rust versuchen, das Erbe von C anzutreten, ohne dessen fatale Fehler zu wiederholen. Sie führen das Konzept der Slices ein. Ein Slice ist nichts anderes als die Kombination aus einem Zeiger und einer explizit gespeicherten Länge. Hier muss niemand mehr im Dunkeln tasten. Das System weiß zu jedem Zeitpunkt, wie groß der Datenblock ist. Es ist eine Rückkehr zur Ehrlichkeit im Design. Wir hören auf zu raten und fangen an zu wissen. Das Erstaunliche ist, dass dieser Ansatz oft sogar schneller ist als das traditionelle Vorgehen in C. Da die Länge bereits bekannt ist, entfällt das ständige Scannen nach dem Null-Byte. Die CPU kann die Daten viel effizienter verarbeiten, weil sie im Voraus weiß, wie viele Iterationen nötig sind. Es ist ein klassisches Beispiel dafür, wie eine vermeintliche Vereinfachung in der Vergangenheit die Leistung in der Gegenwart bremst.
Wer heute noch behauptet, dass die traditionelle Handhabung von Zeichenketten in C alternativlos sei, hat den Anschluss an die Realität verloren. Es ist Zeit, die Nostalgie beiseite zu legen. Wir müssen anerkennen, dass viele der Probleme, mit denen wir in der IT-Sicherheit kämpfen, hausgemacht sind. Sie entspringen einer Zeit, in der Computer so groß wie Räume waren und weniger Rechenleistung hatten als ein moderner Toaster. Diese Ära ist vorbei. Unsere Anforderungen an Robustheit und Sicherheit sind massiv gestiegen. Ein Programm, das seine eigenen Datenstrukturen nicht präzise begrenzen kann, ist in einer vernetzten Welt eine Gefahr für die Allgemeinheit. Es geht nicht nur um ein technisches Detail, sondern um eine Frage der Verantwortung gegenüber den Nutzern.
Man kann die Vergangenheit nicht ändern, aber man kann aufhören, ihre Fehler als Tugenden zu verkaufen. C wird bleiben, keine Frage. Zu viel kritische Infrastruktur läuft auf diesem Code. Aber wir sollten aufhören, so zu tun, als sei die Art und Weise, wie die Len Of String In C ermittelt wird, ein geniales Design. Es war ein Kompromiss, der seine Schuldigkeit getan hat. Heute ist er vor allem eine Altlast, die uns teuer zu stehen kommt. Echte Fachkompetenz zeigt sich nicht darin, wie gut man mit gefährlichen Werkzeugen jonglieren kann, sondern darin, zu erkennen, wann ein Werkzeug durch ein sichereres ersetzt werden muss. Die Komplexität unserer Welt erlaubt uns den Luxus der Unschärfe im Speicher nicht mehr. Jedes Byte zählt, aber die Information über die Anzahl dieser Bytes zählt noch viel mehr.
Wenn wir die Art und Weise, wie wir über Text im Computer nachdenken, nicht grundlegend ändern, werden wir weiterhin dieselben Sicherheitslücken flicken, die schon vor dreißig Jahren bekannt waren. Es ist ein ewiger Kreislauf aus Patch und Exploit, der seine Wurzeln in einem einzigen fehlenden Zähler hat. Wir müssen lernen, Daten als begrenzte Einheiten zu begreifen, deren Ausmaß von Anfang an feststeht, anstatt sie als endlose Ströme zu betrachten, die irgendwo im Nirgendwo enden. Nur so können wir Systeme bauen, die nicht nur schnell, sondern auch vertrauenswürdig sind. Die Eleganz der Einfachheit darf nicht auf Kosten der Korrektheit gehen. Am Ende des Tages ist ein String ohne bekannte Länge kein Text, sondern eine Zeitbombe im Arbeitsspeicher.
Wahre Sicherheit beginnt in der Informatik dort, wo wir aufhören zu hoffen, dass ein Null-Byte uns rettet, und anfangen, die Grenzen unserer Daten explizit zu definieren.



