Es war ein Dienstagnachmittag, kurz vor dem Release eines kritischen Sicherheitsupdates für ein deutsches Fintech-Unternehmen. Ein Junior-Entwickler, nennen wir ihn Lars, saß an seinem Rechner und sollte nur eine kleine Korrektur am Login-Prozess vornehmen. Er dachte sich nichts dabei, als er direkt loslegte. Erst zwei Stunden später bemerkte er, dass er sich auf dem falschen Stand befand und seine Änderungen bereits mit instabilem Code aus einem anderen Experiment vermischt waren. Der Versuch, das Ganze durch Creating A New Branch Git zu retten, kam zu spät. Lars hatte die Basis nicht geprüft. Das Ergebnis? Vier Stunden mühsame Handarbeit, um die Änderungen manuell zu extrahieren, ein verzögerter Release und ein Teamleiter, der kurz vor dem Explodieren stand, weil die Integrität der Versionshistorie zerschossen war. Solche Fehler kosten in der freien Wirtschaft nicht nur Nerven, sondern durch die verschwendete Arbeitszeit hochbezahlter Spezialisten schnell vierstellige Beträge pro Vorfall.
Ich habe das in den letzten zehn Jahren in Projekten jeder Größe erlebt. Es fängt immer harmlos an, aber wer die Mechanik dahinter nicht respektiert, baut sich technische Schulden auf, die irgendwann wie ein Kartenhaus zusammenbrechen. Der Prozess scheint simpel: Ein Befehl, ein Name, fertig. Doch die Realität in der Softwareentwicklung verzeiht keine Nachlässigkeit bei der Strukturierung deiner Arbeitsschritte.
Warum Creating A New Branch Git ohne sauberen Startpunkt reiner Selbstmord ist
Der häufigste Fehler, den ich sehe, ist das blinde Vertrauen in den aktuellen Zustand des Terminals. Entwickler springen zwischen Aufgaben hin und her wie Ping-Pong-Bälle. Sie sind gerade in einem Bugfix, dann kommt ein Anruf wegen eines neuen Features, und zack – sie tippen den Befehl für einen neuen Zweig ein, ohne zu merken, dass sie noch halbfertige, ungetestete Änderungen im Arbeitsverzeichnis haben.
Das Problem dabei ist die Vererbung. Wenn du nicht explizit sicherstellst, dass du von einem stabilen Hauptzweig – meistens main oder develop – startest, schleppst du den Müll des vorherigen Versuchs mit. Ich erinnere mich an ein Projekt bei einem Automobilzulieferer, wo ein ganzes Team drei Tage lang Phantom-Bugs jagte. Am Ende stellte sich heraus, dass jemand einen neuen Zweig von einem kaputten Experiment eines Kollegen abgezweigt hatte, statt vom offiziellen Release-Stand.
Du musst dir angewöhnen, erst einmal "aufzuräumen". Das bedeutet: Den aktuellen Stand sichern oder verwerfen, zum Hauptzweig wechseln und diesen mit dem Server synchronisieren. Erst wenn du sicher bist, dass dein lokaler main-Zweig eins zu eins dem entspricht, was auf dem Server liegt, ist der Moment für den neuen Ableger gekommen. Alles andere ist russisches Roulette mit der Codebasis.
Die Lüge von den sprechenden Namen bei Creating A New Branch Git
Viele denken, ein Name sei nur Schall und Rauch. "Ich nenne das jetzt mal fix-login", sagt sich der Entwickler. Drei Wochen später gibt es fünf Zweige, die so heißen, weil drei verschiedene Leute am Login gearbeitet haben. In einem professionellen Umfeld ist das ein Rezept für Desaster. Wer keine Namenskonventionen nutzt, verbrennt Zeit bei jedem einzelnen Merge-Request, weil niemand mehr weiß, wer was warum gemacht hat.
Gute Teams nutzen Präfixe. Das ist kein unnötiger bürokratischer Aufwand, sondern eine Überlebensstrategie. Ein Zweig sollte immer verraten, was er tut und zu welchem Ticket er gehört. Ein Schema wie feature/JIRA-123-add-paypal-support oder bugfix/issue-456-fix-header-overflow spart dir pro Tag locker 15 Minuten Sucherei. Rechnet man das auf ein Team von zehn Leuten hoch, sprechen wir von über zwei Stunden gewonnener Produktivität am Tag. Einfach nur durch konsequentes Benennen.
Das Risiko der langlebigen Zweige
Ein weiterer fataler Irrtum ist der Glaube, man könne einen Zweig wochenlang offen halten. Ich habe Code-Reviews gesehen, bei denen der Zweig so weit vom Hauptstamm entfernt war, dass die Integration einem chirurgischen Eingriff am offenen Herzen glich. Je länger ein Zweig existiert, desto schmerzhafter wird die Rückführung. Die Regel ist simpel: Wenn dein Zweig älter als zwei Tage ist, hast du deine Aufgabe wahrscheinlich nicht klein genug geschnitten. Kleine, atomare Änderungen sind der Schlüssel. Wer versucht, das komplette Backend in einem Rutsch umzubauen, wird beim Mergen scheitern. Die Konflikte, die dann entstehen, sind oft so komplex, dass Entwickler frustriert "den Kopf in den Sand stecken" und einfach alles mit Gewalt überschreiben, was wiederum neue Fehler produziert.
Der Vorher-Nachher-Vergleich: Chaos versus Struktur
Schauen wir uns an, wie das in der Praxis abläuft. Ein typischer "Chaos-Ansatz" sieht so aus: Der Entwickler arbeitet an Feature A. Plötzlich kommt ein wichtiger Bugfix rein. Er ist zu faul zum Wechseln, erstellt direkt einen neuen Zweig aus Feature A heraus und nennt ihn quickfix. Er schließt den Bugfix ab und schiebt ihn in die Produktion. Doch huch, plötzlich ist auch das halbe, noch kaputte Feature A auf dem Live-Server, weil der quickfix-Zweig ja darauf basierte. Der Shop steht still, Kunden können nicht bezahlen, der Support läuft heiß. Die Kosten? Zehntausende Euro Umsatzverlust innerhalb einer Stunde.
Im Gegensatz dazu der strukturierte Ansatz: Der Entwickler erkennt den Bugfix-Bedarf. Er speichert seine Arbeit an Feature A mit einem temporären Speicherbefehl (Stash). Er wechselt zurück zum sauberen Produktionsstand. Er führt den Befehl für einen neuen Zweig aus, basierend auf dem stabilen Code. Er fixiert den Fehler, testet ihn isoliert und mergt ihn zurück. Danach kehrt er zu Feature A zurück, holt sich den neuen Fix kurz ab und arbeitet weiter. Die Produktion bleibt sauber, die Historie ist logisch nachvollziehbar, und der Stresspegel bleibt im grünen Bereich. Das ist der Unterschied zwischen einem Profi und jemandem, der nur Code tippt.
Die Falle der lokalen versus entfernten Sichtbarkeit
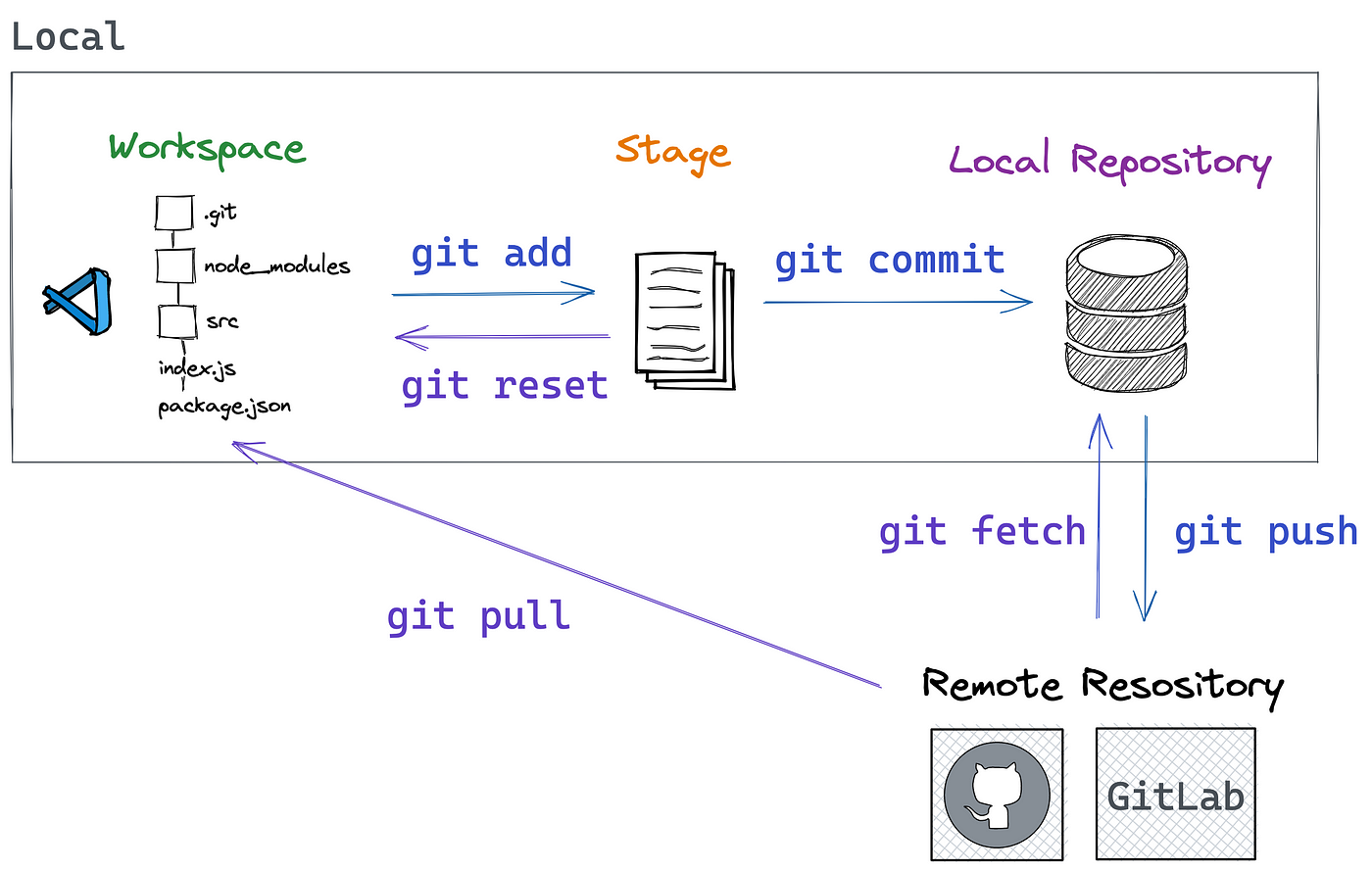
Ein Fehler, der besonders Anfänger in den Wahnsinn treibt, ist die Diskrepanz zwischen dem eigenen Rechner und dem Server. Nur weil du lokal einen Zweig erstellt hast, weiß die Welt noch nichts davon. Das führt oft zu der Situation, dass Kollegen verzweifelt nach deinem Code suchen, während du schwörst, dass du ihn erstellt hast.
Es gibt diesen Moment, wenn man den Befehl zum Hochladen eingibt und Git sich beschwert, dass kein "Upstream" gesetzt ist. Viele kopieren dann einfach blind den Vorschlag von Git in das Terminal. Das klappt zwar, zeigt aber, dass das Grundverständnis fehlt. Du musst verstehen, dass deine lokale Arbeit so lange irrelevant ist, bis sie auf dem zentralen Server – sei es GitLab, GitHub oder Bitbucket – landet. In meiner Zeit als Berater habe ich erlebt, wie ein kompletter Sprint-Abschluss scheiterte, weil drei Entwickler ihre Zweige zwar lokal erstellt und bearbeitet, aber vergessen hatten, sie korrekt zu verknüpfen und hochzuladen. Sie dachten, ein "Commit" würde reichen. Ein teurer Irrtum, wenn am nächsten Morgen die Präsentation beim Kunden ansteht und der Server den Stand von vor drei Tagen anzeigt.
Warum "Git Flow" oft zu viel des Guten ist
In vielen Blogs wird "Git Flow" als das ultimative Modell gepriesen. In der Theorie klingt das super: feature, release, hotfix, develop, master. In der harten Praxis vieler kleiner und mittelständischer Unternehmen ist das oft wie mit Kanonen auf Spatzen zu schießen. Ich habe Firmen gesehen, die durch diesen Prozess so verlangsamt wurden, dass sie für eine Textänderung auf der Website drei Stunden brauchten, weil sie durch fünf verschiedene Zweige und zwei Freigabeprozesse gehen mussten.
Für die meisten Teams reicht ein vereinfachtes Modell. Wer Creating A New Branch Git als Werkzeug nutzt, sollte es so komplex wie nötig, aber so einfach wie möglich halten. Wenn du ein kleines Team von drei Leuten bist, brauchst du keine fünf permanenten Zweige. Du brauchst einen stabilen Stamm und kurzlebige Feature-Zweige. Alles andere erzeugt nur administrativen Overhead, den niemand bezahlt. Es geht darum, Software zu liefern, nicht die schönste Zweig-Struktur der Welt im Lebenslauf stehen zu haben.
Realitätscheck: Was du wirklich beherrschen musst
Hören wir auf mit den Illusionen. Die Arbeit mit Versionierungssystemen ist kein Selbstzweck. Es ist ein Sicherheitsnetz. Wer behauptet, er beherrsche das Thema nach einem Nachmittag Tutorial, lügt sich selbst an. Die wahre Meisterschaft zeigt sich dann, wenn es knallt. Wenn du zwei Zweige hast, die beide die gleiche Datei an 50 Stellen geändert haben, und du jetzt entscheiden musst, welcher Code überlebt.
Um wirklich sicher zu navigieren, musst du folgendes akzeptieren:
- Disziplin ist wichtiger als Intelligenz. Du kannst der beste Programmierer der Welt sein – wenn du deine Zweige nicht ordentlich trennst, wirst du dein Team sabotieren. Es ist eine Frage der Arbeitsmoral, vor jedem neuen Schritt den Status zu prüfen.
- Werkzeuge ersetzen kein Denken. GUIs wie Sourcetree oder GitKraken sind nett anzusehen, aber sie verstecken oft, was im Hintergrund passiert. Du musst die Befehle im Terminal verstehen, sonst bist du aufgeschmissen, wenn das Programm mal eine Fehlermeldung ausgibt, die nicht in die hübsche Oberfläche passt.
- Fehler werden passieren. Du wirst auf dem falschen Zweig arbeiten. Du wirst vergessen zu pushen. Der Punkt ist: Lerne, wie du es reparierst, ohne den
rm -rf-Hammer auszupacken und alles neu zu klonen. Lerne Befehle wiecherry-pickoderrebase. Das sind die Werkzeuge, die den Junior vom Senior unterscheiden.
Git verzeiht vieles, aber Ignoranz gegenüber dem Workflow gehört nicht dazu. Wer hier spart, zahlt später mit Überstunden und technischer Insolvenz. Es ist nun mal so: Ein sauberer Start ist die halbe Miete. Wenn du das nächste Mal davor stehst, eine neue Aufgabe zu beginnen, atme kurz durch, prüfe deinen Stand und mach es verdammt noch mal richtig. Dein zukünftiges Ich wird es dir danken, wenn es am Freitagabend um 17:00 Uhr nicht vor einem Scherbenhaufen aus Merge-Konflikten sitzt.



