Stell dir vor, du blickst auf eine Tankanzeige, die dir versichert, dass der Tank noch halbvoll ist, während der Motor deines Wagens bereits die ersten qualvollen Aussetzer zeigt. In der Welt der Systemadministration ist das kein Albtraum, sondern der Alltag vieler Nutzer, die blind auf die Standardwerkzeuge vertrauen. Wer versucht, Check Free Disk Space In Linux als simple Rechenaufgabe zu verstehen, hat den ersten Schritt in eine technologische Falle bereits getan. Die meisten Anwender glauben, dass ein einfacher Befehl wie df die nackte Wahrheit über den Zustand ihrer Speichermedien ans Licht bringt. Sie wiegen sich in Sicherheit, wenn das System meldet, dass noch zwanzig Prozent Kapazität verfügbar sind. Doch diese Zahl ist eine gefährliche Vereinfachung, eine Abstraktion, die die physikalische Realität der Datenverwaltung auf modernen Dateisystemen fast schon böswillig ignoriert. Der Speicherplatz in einem Linux-System ist keine statische Badewanne, die man einfach füllt oder leert, sondern ein dynamisches, hochkomplexes Ökosystem, in dem Bits und Bytes verschwinden können, ohne dass die Anzeige es merkt.
Die Lüge der freien Blöcke und die Macht der Metadaten
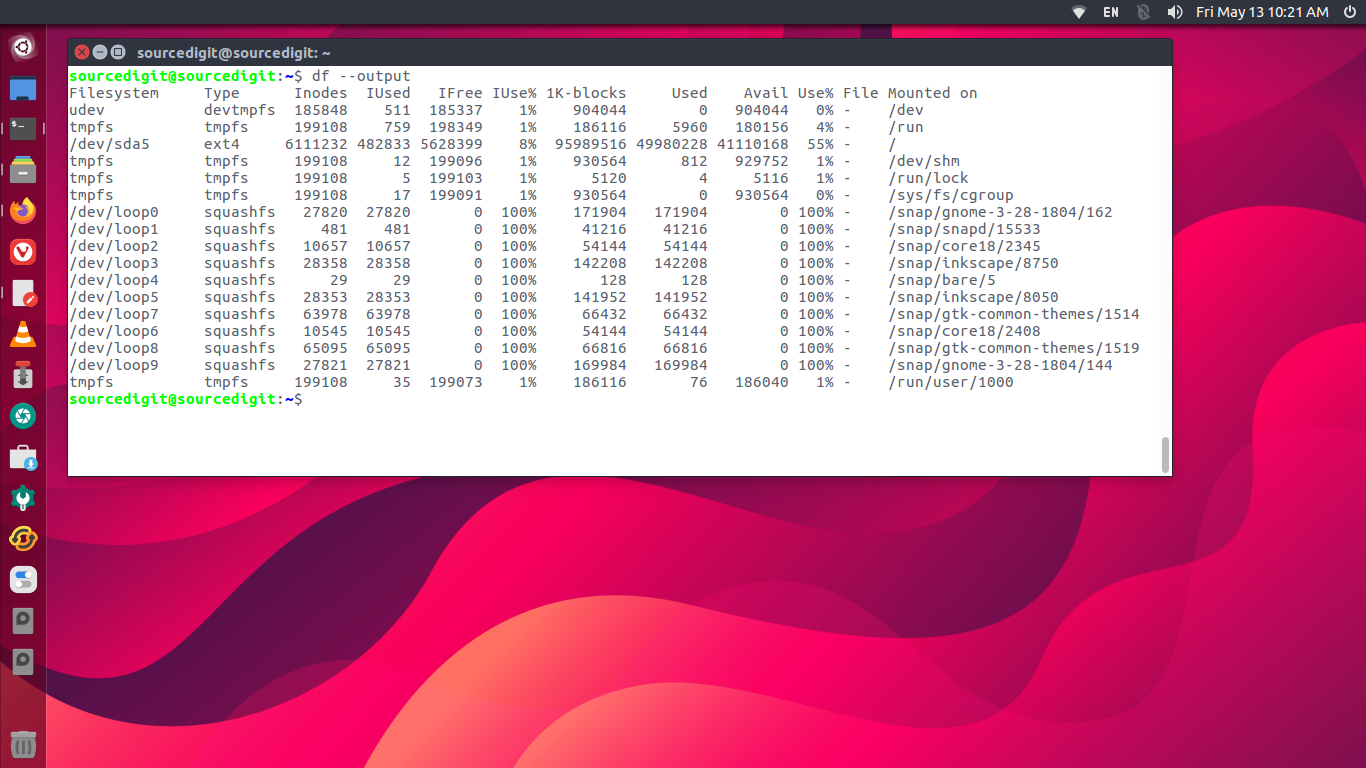
Das Problem beginnt tief im Kern des Dateisystems, dort, wo die Buchhaltung geführt wird. Wenn du ein herkömmliches Werkzeug nutzt, um den freien Platz zu prüfen, fragt dieses Tool im Grunde nur beim Superblock des Dateisystems nach, wie viele Datenblöcke als frei markiert sind. Das klingt logisch, ist aber in der Praxis oft irreführend. Ein klassisches Ext4-Dateisystem reserviert standardmäßig fünf Prozent des gesamten Platzes für den Root-Nutzer. Diese Reserve taucht in der normalen Anzeige oft gar nicht als verfügbarer Platz für den Endanwender auf. Plötzlich wunderst du dich, warum dein System den Dienst quittiert, obwohl die Anzeige behauptet, es sei noch Platz vorhanden. Diese reservierten Blöcke sind eine Lebensversicherung für das System, damit ein normaler Prozess die Platte nicht so weit füllt, dass sich nicht einmal mehr der Administrator einloggen kann, um den Müll zu löschen. Wer diese Nuancen ignoriert, behandelt seinen Server wie ein Spielzeug und nicht wie ein Präzisionswerkzeug.
Noch tückischer wird es, wenn wir über Inodes sprechen. Stell dir das Dateisystem wie eine riesige Bibliothek vor. Die Inodes sind die Karteikarten im Katalog. Jede Datei, egal ob sie ein Terabyte groß ist oder nur ein einziges Byte enthält, benötigt genau eine Karteikarte. Wenn du Millionen von winzigen Dateien erzeugst, etwa durch exzessives Logging oder schlecht konfigurierte Cache-Verzeichnisse, kann es passieren, dass dir die Karteikarten ausgehen, während die Regale der Bibliothek noch fast leer sind. Du hast dann gigabyteweise freien Platz, kannst aber keine einzige neue Datei mehr anlegen. Das System wird dir eine Fehlermeldung ausspucken, die besagt, dass kein Speicherplatz mehr verfügbar ist. Ein naiver Blick auf die Kapazität wird dich in diesem Moment völlig ratlos zurücklassen. In der professionellen IT-Welt ist das Erschöpfen von Inodes ein klassischer Fehler, der zeigt, dass man die zugrunde liegende Struktur nicht verstanden hat. Es ist ein strukturelles Versagen der Wahrnehmung.
Warum Check Free Disk Space In Linux keine einfache Metrik ist
Die Komplexität nimmt massiv zu, sobald moderne Speichertechnologien wie Btrfs oder ZFS ins Spiel kommen. In diesen Umgebungen ist die klassische Vorstellung von freiem Platz nahezu hinfällig. Dank Mechanismen wie Copy-on-Write, Snapshots und Kompression weiß das System oft selbst erst in dem Moment, in dem die Daten tatsächlich auf die Platten geschrieben werden, wie viel Platz sie wirklich verbrauchen werden. Wenn du einen Snapshot erstellst, verbraucht dieser im ersten Moment fast gar keinen zusätzlichen Platz. Erst wenn du Dateien im Originalverzeichnis änderst oder löschst, beginnt der Snapshot zu wachsen, weil er die alten Zustände der Blöcke bewahren muss. In einer solchen Umgebung ist das Vorhaben Check Free Disk Space In Linux eher mit einer Wettervorhersage als mit einer präzisen Messung zu vergleichen. Du hantierst mit Wahrscheinlichkeiten und Schätzungen.
Das Phantom der gelöschten Dateien
Ein Phänomen, das regelmäßig für Verwirrung sorgt, sind Dateien, die gelöscht wurden, deren Platz aber nicht freigegeben wird. Das passiert immer dann, wenn ein laufender Prozess die Datei noch geöffnet hält. Du löschst eine riesige Log-Datei von zehn Gigabyte, aber dein Monitoring-Tool zeigt weiterhin an, dass die Platte voll ist. Warum ist das so? Das Betriebssystem entfernt zwar den Namen der Datei aus dem Verzeichnisbaum, aber solange der Prozess den Dateideskriptor hält, bleiben die Datenblöcke auf der Festplatte reserviert. Erst wenn der Prozess beendet wird oder die Datei explizit schließt, wird der Platz wirklich frei. In einer Welt, in der Verfügbarkeit alles ist, kann ein solches Missverständnis dazu führen, dass Administratoren panisch neue Festplatten kaufen, während die Lösung eigentlich nur im Neustart eines hängengebliebenen Dienstes bestanden hätte.
Die Falle der Sparse-Files
Es gibt auch den umgekehrten Fall: Dateien, die auf dem Papier riesig sind, aber in der Realität kaum Platz beanspruchen. Diese sogenannten Sparse-Files enthalten große Bereiche aus Nullen, die das Dateisystem intelligent optimiert, indem es sie einfach gar nicht speichert. Wenn du ein Disk-Image für eine virtuelle Maschine erstellst, das nominell hundert Gigabyte groß ist, belegt es auf der physischen Platte vielleicht nur zwei Gigabyte, solange das Gast-System leer ist. Wenn du nun versuchst, den Platzbedarf durch einfaches Addieren der Dateigrößen zu ermitteln, wirst du eine Zahl erhalten, die weit über der tatsächlichen Kapazität deiner Hardware liegt. Das ist kein Fehler, sondern ein Feature, das jedoch eine völlig neue Ebene der Aufmerksamkeit erfordert. Wer diese Unterschiede nicht sauber trennen kann, wird früher oder später von der harten Realität der Hardwarekapazitäten eingeholt.
Die Arroganz der grafischen Benutzeroberflächen
Viele Nutzer flüchten sich in grafische Tools, die mit hübschen Tortendiagrammen und Fortschrittsbalken locken. Diese Werkzeuge sind oft die schlimmsten Übeltäter, wenn es um die Verzerrung der Realität geht. Sie abstrahieren so viel weg, dass am Ende nur noch eine trügerische Sicherheit bleibt. Sie berechnen oft den Platz im Papierkorb nicht mit ein oder ignorieren versteckte Mount-Points und Netzwerkfreigaben. Ich habe es oft erlebt, dass Anwender völlig verzweifelt vor ihrem Rechner saßen, weil der Dateimanager behauptete, die Festplatte sei leer, während die Konsole vor Fehlern überquoll. Die Wahrheit liegt niemals in einem bunten Balken, sondern in der Fähigkeit, die Ausgabe von spezialisierten Werkzeugen im Kontext der Mount-Optionen und der Dateisystem-Features zu lesen.
Ein oft übersehener Aspekt ist die Fragmentierung, auch wenn Linux-Dateisysteme wie Ext4 hier sehr effizient arbeiten. Auf einer fast vollen Festplatte muss das System jedoch immer größere Anstrengungen unternehmen, um noch zusammenhängende Blöcke zu finden. Das führt zu einer massiven Leistungseinbuße, noch bevor die Platte rechnerisch bei hundert Prozent Belegung angekommen ist. Ein System mit neunundneunzig Prozent Auslastung verhält sich völlig anders als eines mit fünfzig Prozent, selbst wenn die Datenmenge identisch ist. Es geht nicht nur darum, ob Platz da ist, sondern wie zugänglich dieser Platz ist. Wer nur auf die nackte Zahl schaut, ignoriert den Verschleiß und die Latenz, die durch ein zu volles Dateisystem entstehen. Es ist wie in einem Lagerhaus: Wenn jeder Gang mit Kisten vollgestellt ist, kannst du zwar theoretisch noch eine weitere Kiste unterbringen, aber du wirst Stunden brauchen, um sie wieder herauszuholen.
Die Notwendigkeit einer neuen Perspektive auf Speicher
Wir müssen aufhören, Speicher als eine eindimensionale Ressource zu betrachten. Es ist an der Zeit, dass wir uns von der Vorstellung verabschieden, dass ein einziger Wert ausreicht, um den Gesundheitszustand eines Systems zu bewerten. Wir brauchen eine ganzheitlichere Sichtweise, die Inodes, Snapshots, Reserven und offene Dateideskriptoren mit einbezieht. Die Werkzeuge sind da, aber sie verlangen nach einem Nutzer, der bereit ist, unter die Oberfläche zu blicken. Wenn man sich die Statistiken von großen Cloud-Providern oder Rechenzentren ansieht, wird klar, dass Speichermangel einer der häufigsten Gründe für ungeplante Ausfallzeiten ist. Und in fast allen Fällen war nicht der Mangel an Hardware das Problem, sondern die Unfähigkeit der Betreiber, die Warnsignale richtig zu deuten, die ihnen ihre Systeme lieferten.
Es gibt namhafte Experten in der Linux-Community, die seit Jahren fordern, dass wir die Art und Weise, wie wir über Kapazität kommunizieren, grundlegend ändern müssen. Wir brauchen keine Tools, die uns sagen, wie viele Bytes noch da sind. Wir brauchen Systeme, die uns sagen, wie lange wir bei der aktuellen Nutzungsrate noch sicher operieren können, bevor die strukturellen Grenzen des Dateisystems uns in die Knie zwingen. Das ist der Unterschied zwischen Daten und Information. Daten sind das, was dir ein simpler Befehl liefert. Information ist das, was du daraus machst, wenn du die Architektur des Kernels und der Speicherschichten verstehst.
Die Realität ist, dass ein Linux-System dir niemals die ganze Wahrheit auf dem Silbertablett serviert. Es gibt dir Fragmente, Hinweise und Rohdaten. Es liegt an dir, diese Zeichen zu deuten. Wer glaubt, dass er mit einem schnellen Kommando alles im Griff hat, wird beim nächsten großen Systemcrash unsanft geweckt werden. Es ist die Hybris des modernen Nutzers, zu glauben, dass Komplexität durch eine einfache Zahl gebändigt werden kann. In Wahrheit ist der freie Platz auf deiner Festplatte eine flüchtige Illusion, die nur so lange Bestand hat, bis das erste Bit am falschen Ort landet.
Echter Speicherplatz ist keine Zahl auf einem Bildschirm, sondern das fragile Gleichgewicht zwischen physischen Grenzen und der unsichtbaren Logik deiner Datenstruktur.



